随着人工智能的迅速发展,深度学习模型日益复杂,资源消耗问题也随之凸显。模型蒸馏技术通过将大型模型的知识转移到较小模型中,有效解决了模型在资源受限环境下的部署与应用难题,不仅提升了推理效率,还显著降低了计算成本。这项技术在移动设备和边缘计算领域展现出巨大潜力,同时也面临着优化知识转移和超参数调优等挑战。
基本原理与发展历程
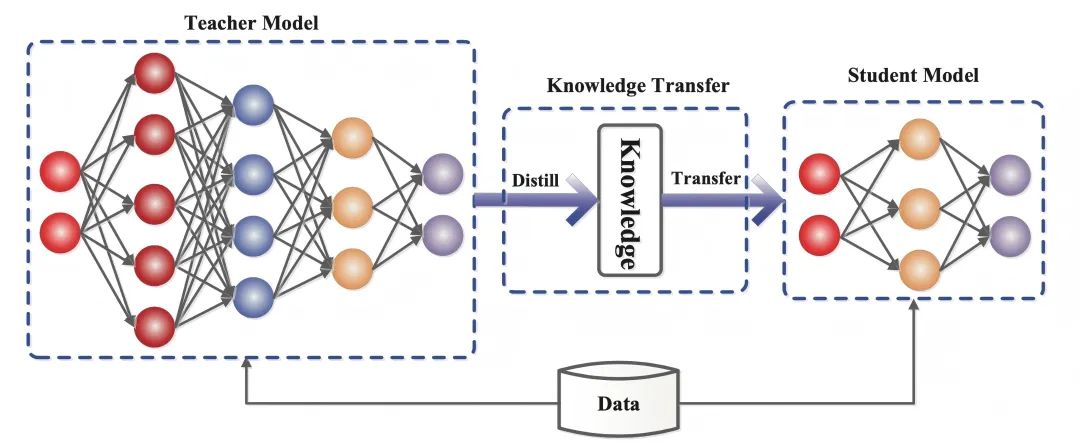
模型蒸馏技术的核心在于将复杂模型的知识精华提取并转移到轻量级模型中。随着深度学习的发展,该技术在2015年由深度学习先驱杰弗里·辛顿(Geoffrey Hinton)提出知识蒸馏概念后取得重大突破。这种方法使得大型神经网络的智慧能够被浓缩到资源需求更低的小型模型中,特别适合在移动设备等资源受限环境中应用。

核心技术方法
模型蒸馏主要包括四种关键方法:知识蒸馏、整体蒸馏、自蒸馏和软标签方法。知识蒸馏是最基础的方法,通过让小模型学习大模型的输出来传递知识;整体蒸馏强调大小模型的协同学习;自蒸馏实现模型的自我优化;软标签方法则提供更细腻的知识传递机制。
应用优势与技术挑战
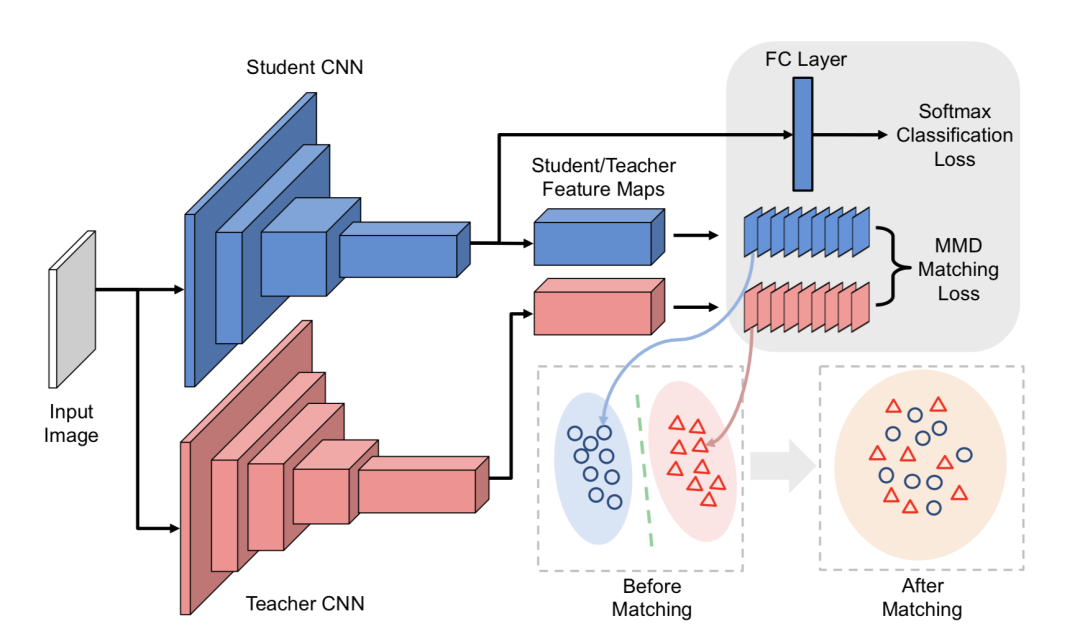
在实际应用中,模型蒸馏技术显著提升了推理速度,降低了内存占用,使复杂人工智能功能能够在移动设备上高效运行。然而,该技术在知识转移精确度和参数优化方面仍面临挑战,需要持续改进和创新。
技术发展趋势
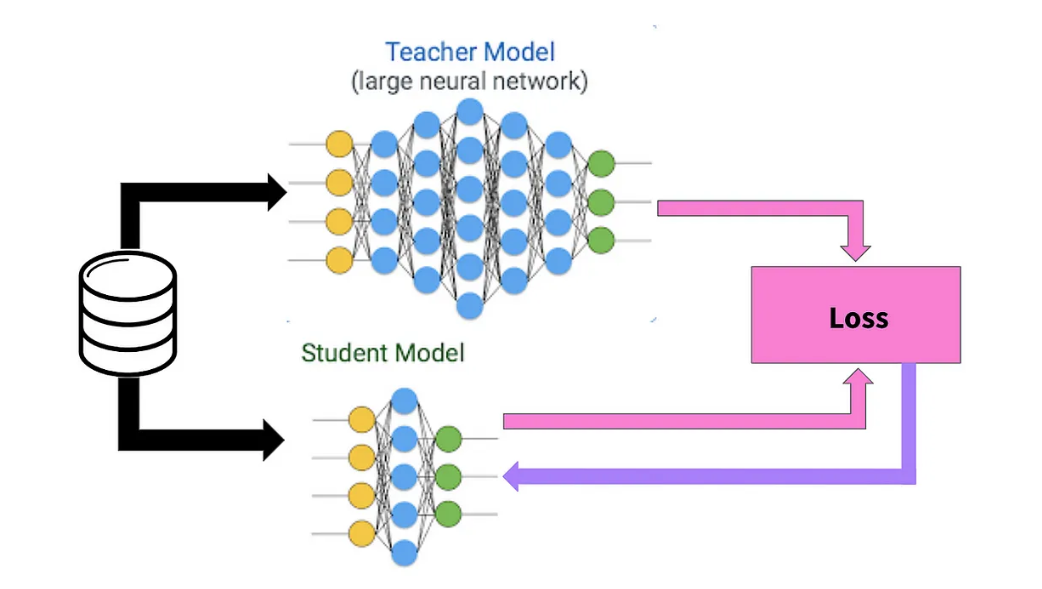
模型蒸馏技术正向多模态融合、自适应学习等方向发展。新趋势包括将图像、文本和音频等多种数据类型整合到轻量级模型中,以及结合强化学习的创新策略,为人工智能应用开辟更广阔前景。
实践应用案例
模型蒸馏技术已在智能手机、语言翻译、医疗诊断和自动驾驶等领域取得显著成果。具体应用包括智能手机实时场景识别、医疗领域快速异常检测、自动驾驶实时环境分析等,展示了该技术在实际场景中的巨大潜力。